Gestion des URLs de K-Sup
La fonctionnalité de gestion des URLs permet de disposer pour chaque contenus d'URL propre et spécifique. Cette fonctionnalité permet également d'administrer des URLs courtes.
Fonctionnement
Vue globale
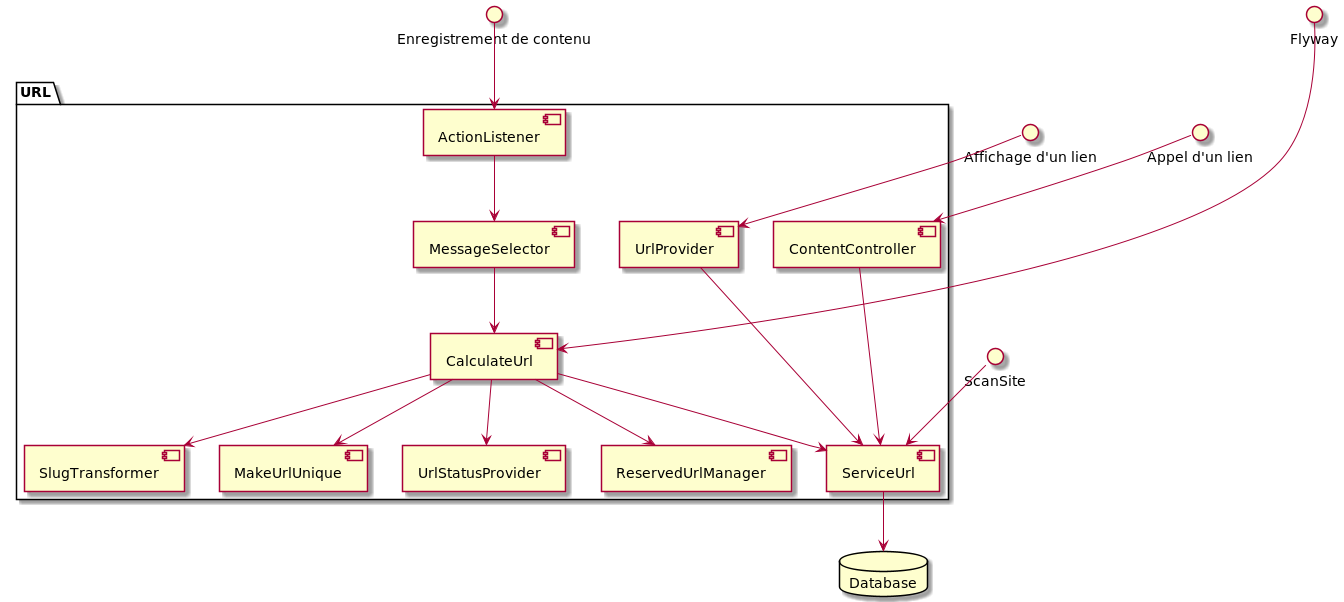
Dans ce schéma on peut voir les différents éléments qui composent la gestion des URLs.
Points d'entrées
Différents acteurs intéragissent avec les URLS (utilisateurs ou acteurs techniques) :
- Enregistrement d'un contenu : quand un utilisateur sauvegarde une rubrique, une fiche ou un site, les URLs qui sont liées à ce contenu sont impactées
- Affichage d'un lien : quand on affiche une page qui fait un lien vers un contenu, il faut savoir quelle URL de ce contenu va être affichée
- Appel d'un lien : à chaque clic sur un lien, on cherche à retrouver le contenu qui lui est associé afin de l'afficher à l'utilisateur
- Flyway : de manière automatique, au premier démarrage de l'application les URLs sont calculées, mais il est également possible de créer des scripts qui vont demander un recalcul
- ScanSite : chaque nuit l'application réalise un traitement sur les URLs (Suppression des urls obsolètes).
Messages spring
À chaque enregistrement d'un contenu, un message spring est lancé sur le canal de communication global de l'application. Des écouteurs ont été mis en place afin d'identifier ceux qui intéressent le calcul d'URL.
Ils sont filtrés par des sélecteurs afin d'éviter les recalculs non nécessaires.
Traitements
Les différents éléments seront détaillés plus bas, voici comment on peut les résumer :
SlugTransfomer : S'occupe de transformer le slug saisie par l'utilisateur pour le faire "entrer dans le moule K-sup"
MakeUrlUnique : Se charge de vérifier l'unicité d'une URL et le cas échéant d'ajouter un incrément
UrlStatusProvider : Élément calculant le status d'une URL
ReservedUrlManager : Gestionnaire des URLs techniques ou non réservées par l'application
Modèle Objets
On distingue deux tables dans la base de données pour l'enregistrement des données liées aux URLs.
En complément de ces deux tables, il faut noter la présence d'un champs SLUG dans les différentes tables liées aux différents contenus de l'application (RUBRIQUE, METATAG, ARTICLE ...).
Table URL
Table principale de la gestion des URLs.
| Champ | Description |
|---|---|
| ID_URL | Identifiant de l'URL |
| FIRST_VISIBLE_SECTION | Première rubrique visible de l'URL |
| CODE_SITE | Code du site |
| URL | URL de l'URL |
| HASH | Identifiant de l'URL fabriqué en hachant celui-ci |
| TYPE | Type de l'URL |
| STATUS | Statut de l'URL |
| ID_METATAG | Identifiant de la fiche liée à cette URL, peut être null |
| CREATION_DATE | Date de création |
| UPDATE_DATE | Date de mise à jour |
| ID_TARGET_URL | Dans le cas d'une URL de redirection, identifiant de l'URL vers lequel cette URL redirige |
| ID_CANONICAL_URL | Identifiant de l'URL canonique du contenu |
| SECTION | Rubrique du contenu |
Table URL_REDIRECT
Table permettant de tracer les appels des URLs de redirection.
| Champ | Description |
|---|---|
| ID_URL_REDIRECT | Identifiant de l'URL de redirection |
| ID_URL | Identifiant de l'URL qui lui est lié |
| LAST_USED | Dernière date à laquelle l'URL a été utilisée |
| HITS | Nombre de fois où l'URL a été appelée |
Services et accès à la base de données
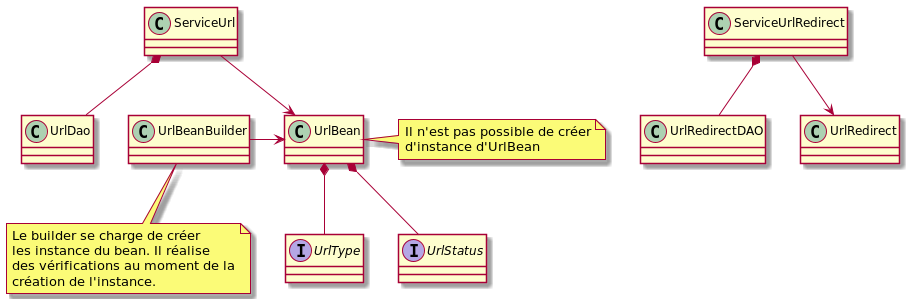
Pour accéder aux données de la base, une couche classique de service et de DAO a été mise en place pour les deux tables citées ci-dessus.
Une particularité a cependant été mise en place concernant la création d'instance d'UrlBean. Il n'est pas possible de créer de telles instances. Pour créer un UrlBean, il faut passer par le UrlBeanBuilder qui réalise des vérifications au moment de la création de l'instance.
Cette dernière classe renseigne également de manière automatique certaines données lorsqu'elles sont nécessaires (date de modification, date de création, hash, id, première visible)
ContentController
La classe ContentController est le point d'entrée principal de l'application. Chaque fois qu'une URL de contenu est appelée, c'est ce controller qui répond. Il se charge de récupérer depuis la base de données l'URL appelée et de renvoyer, en fonction du contenu qui lui est associée, la page correspondante.
C'est également ce controller qui se charge de réaliser la redirection dans le cas de l'appel d'une URL au statut redirect.
Enfin, si aucune URL n'est trouvée, ou si son statut ne permet pas un affichage, il se charge de renvoyer une erreur 404.
UrlProvider
L'URLProvider est l'élément qui se charge de fournir une URL quand on cherche à afficher un lien vers un contenu (par exemple dans une liste de fiches, ou un lien dans un menu etc).
Afin de répondre aux différentes règles métier de l'affichage d'une URL, une chaîne de responsabilité a été mise en place.
 Chaque maillon de la chaîne de responsabilité est un enfant de la classe abstraite UrlProviderProcessor. Chacun se charge de vérifier dans un premier temps s'il est en mesure d'appliquer sa règle métier, si ce n'est pas le cas, il passe la main au maillon suivant. S'il peut y répondre, il applique sa règle et renvoie l'URL.
Chaque maillon de la chaîne de responsabilité est un enfant de la classe abstraite UrlProviderProcessor. Chacun se charge de vérifier dans un premier temps s'il est en mesure d'appliquer sa règle métier, si ce n'est pas le cas, il passe la main au maillon suivant. S'il peut y répondre, il applique sa règle et renvoie l'URL.
C'est la classe UrlProviderChainController qui se charge du rôle de chef d'orchestre. Il crée la chaîne de responsabilité dans un ordre précis et identifie les points d'entrées possibles (avec ou sans rubrique forcée) afin de proposer les différents modes de calcul.
Enfin, UrlProvider est le point d'entrée à ce module. Il est d'ailleurs la seule classe visible du package contenant l'ensemble des classes présentes ci-dessus.
Module d'écoute des actions
Grâce au tissage d'aspect, un grand nombre d'actions effectuées sur l'application sont interceptées et transmettent des messages sur un canal de communication globale à l'application. Il est possible de voir l'ensemble des écouteurs présents dans le fichier publish-interceptor.xml.
Des écouteurs sont présents dans l'application, ceux-ci écoutent les messages qui passent sur ce canal principal, et quand un message les intéresse, il lance une action. C'est le cas pour les URLs à travers le fichier url-subscribe.xml.
Cependant, afin de s'assurer que les actions nécessitent un recalcul d'URL, des filtres sont appliqués, sur la base des informations présentes dans le message transmis, les messages qui intéressent le calcul d'URL.
Par exemple la modification du contenu d'une toolbox n'intéresse pas le calcul d'URL, en revanche la modification de son slug implique directement ses URLs.
Ces objets sont les message selector. Il en existe un pour chaque contenu pouvant impacter les URLs :
- MetatagUrlSelector
- SectionUrlSelector
- SiteUrlSelector
Ceux-ci se chargent donc de vérifier si la DSI ou le slug ou les niveaux montant et descendant des sites etc ont été modifiés.
Transformation de slug
De manière historique, tous les caractères ne sont pas autorisés dans les URLs. Certains vont être transformés, d'autres supprimés.
Ci-dessous la table d'association des caractères :
| Gamme/caractère | Transformation |
|---|---|
| a – z | aucune |
| 0 – 9 | aucune |
| - | aucune |
| A – Z | a - z |
| À, Á, Â, à, á, â | a |
| È, É, Ê, Ë, è, é, ê, ë | e |
| Ì, Í, Î, Ï, ì, í, î, ï | i |
| Ò, Ó, Ô, ò, ó, ô | o |
| Ù, Ú, Û, Ü, ù, ú, û, ü | u |
| Ç ç | c |
| Ñ, ñ | n |
| Æ, æ | ae |
| Œ, œ | oe |
| !, ?, ,, ;, ., :, _, , /, , ~ | - |
| {, }, ’, ,, [, ], &, ^, ¨, *, €, $, £, #, ', ", `, @, =, +, <, >, |, %, (, ) | <vide> |
| Le reste des caractères | encodage en pourcent |
Pour réaliser ceci, des objets de transformation de caractère ont été créés.
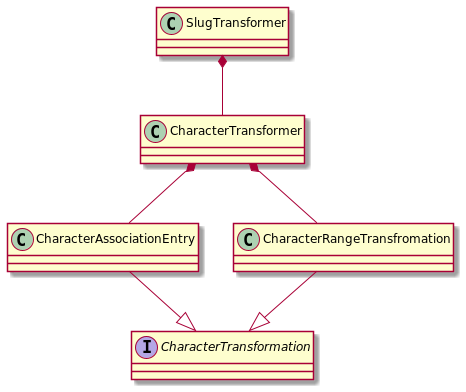
L'interface CharacterTransformation défini comment un objet de transformation doit être écrit. On a donc deux objets de transformation possibles, ceux qui prennent en entrée une fourchette de caractères, et ceux qui prennent un ou plusieurs caractères.
La classe CharacterTransformer instancie les différent éléments de transformations. Enfin SlugTransformer, qui est le point d'entrée de cette fonctionnalité, transforme l'ensemble des caractères d'une chaîne qu'on lui transmet.
Gestion de l'unicité des URLs
Un composant en particulier s'occupe de l'unicité des URLs, il s'agit de MakeUrlUnique. Il prend en paramètre une URL, et se charge de regarder s'il existe déjà une même URL. Si c'est le cas, un incrément est ajouté à la fin de l'URL jusqu'à ce qu'on se retrouve avec une URL qui n'existe pas.
Un incrément max (9999) est déclaré dans la classe afin d'éviter d'itérer sur l'URL à l'infini.
Gestion des URLs réservées de l'application
Au sein de l'application il existe trois types d'URLs réservées :
- Les URLs réservées par paramétrage, il est possible d'en ajouter via un ListToAddBean sur la liste parametrizedReservedUrlList du bean reservedUrlManager
- Les URLs techniques réservées, il s'agit de toutes les URLs des différents controllers de l'application ainsi que les URLs de base des différentes extensions
- Les URLs de site réservées. Ces URLs sont déclarées directement sur la configuration des sites et permettent de bloquer certaines URLs à toute utilisation par une fiche.
Fournisseur de première rubrique visible
La classe FirstVisibleCalculator est appelée directement par l'UrlBeanBuilder dans le but de fournir une première rubrique visible. Elle se charge de remonter l'arbre de la rubrique de l'URL afin de déterminer quelle est la première rubrique parente visible.
Fournisseur de statut d'URL
Cette fonctionnalité permet de fournir un statut pour une URL.
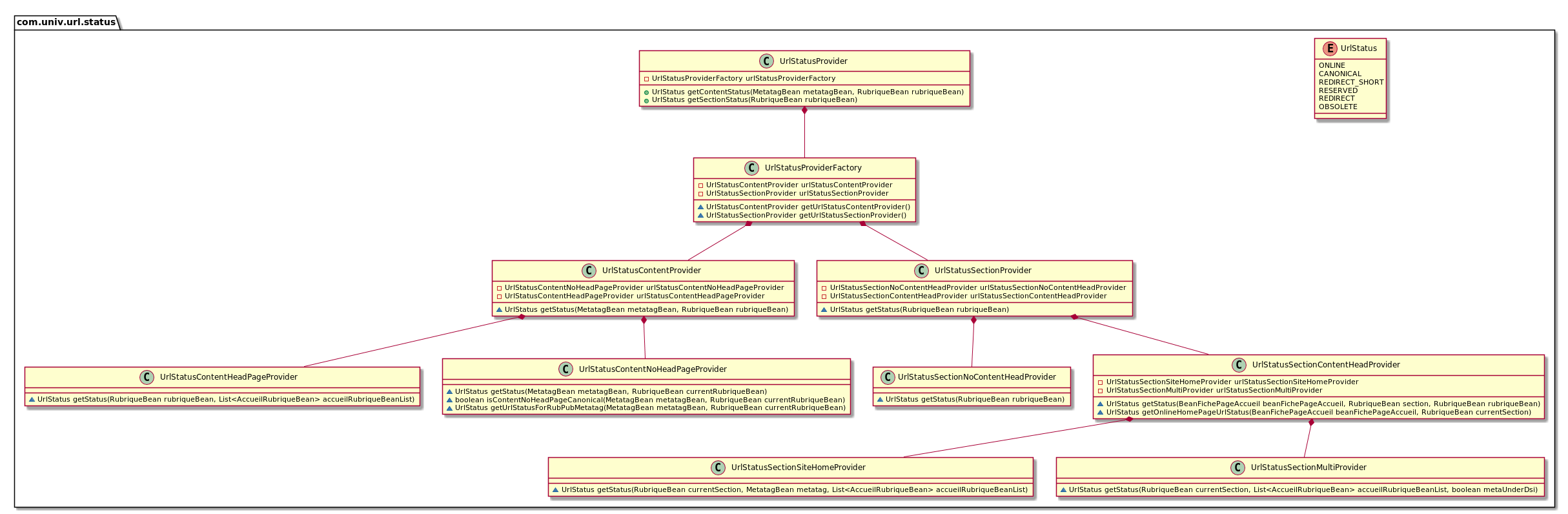
Deux classes sont visibles dans ce package, UrlStatus qui est l'énumération proposant les différents statuts (voir Définition des statuts), et UrlStatusProvider qui est le point d'entrée du calcul de statut.
Dans le schéma ci-dessus on peut voir les interconnexions entre les différents éléments. Quand une des classe n'est pas en mesure de répondre elle va appeler la classe en-dessous elle pour lui demander de fournir un statut à l'URL.
Calcul des URLs
Le calcul des URLs est un traitement coûteux en terme de ressource. L'idée est que ce traitement soit fait au moment de l'enregistrement des contenus afin qu'au moment de sa consultation, aucun traitement de recalcul d'URL ne soit effectué.
Points d'entrées et relais
Le point d'entrée principal du calcul d'URL est la classe CalculateUrlTaskListener. C'est cette classe qui est appelée quand un message (voir module d'écoute des actions) est intercepté et accepté par le module. Elle se charge alors de relayer l'appel vers l'objet de traitement qui correspond.
FullCalculateUrlTask est également un point d'entrée, celui-ci peut être appelé par flyway, mais il est surtout appelé par le job de recalcul d'URL disponible dans le backoffice.
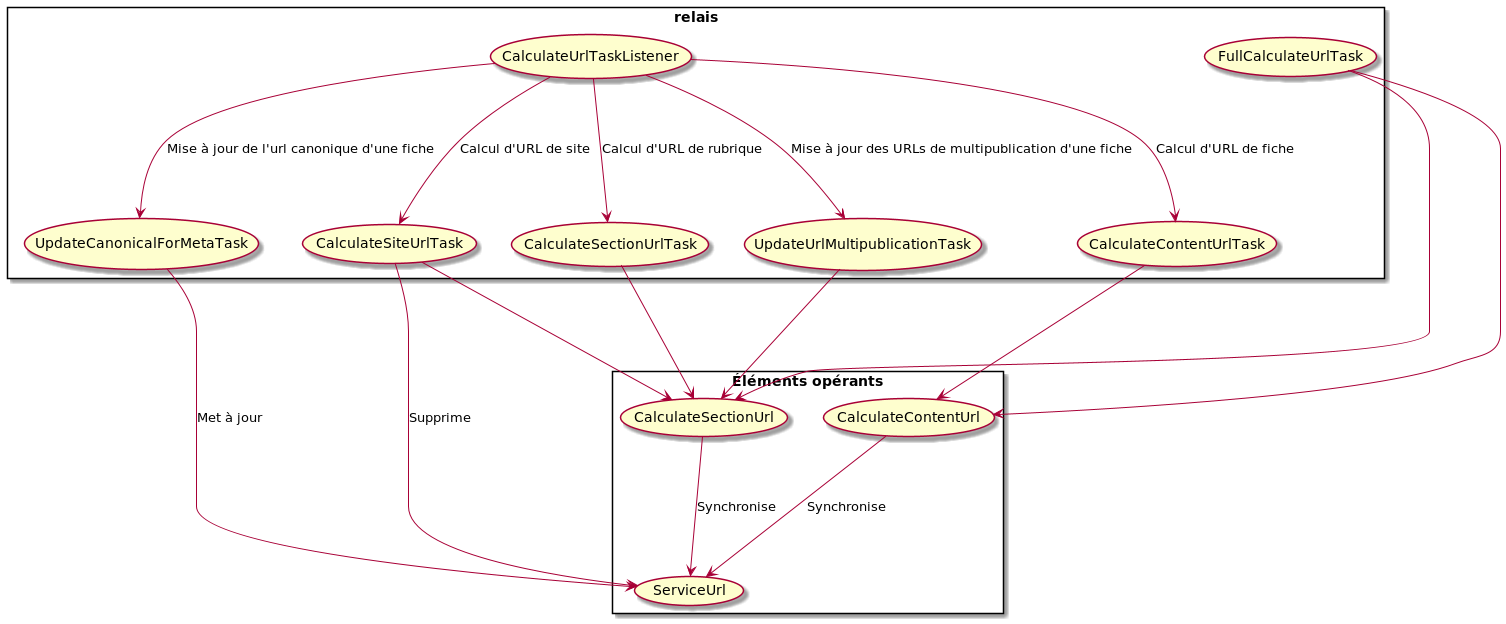
Ce schéma permet de tracer comment les appels sont relayés jusqu'aux principaux services opérants CalculateSectionUrl, CalculateContentUrl et ServiceUrl.
Généralités à propos du calcul
Que ce soit pour le calcul d'URL de rubrique ou de fiche, la même manière de procéder est utilisée. On calcul dans un premier temps la liste des URLs impactées par la modification à l'origine du calcul sans s'intéresser aux URLs déjà présentes en base, puis cette liste est synchronisée (c'est à dire mise en conformité avec les données existantes puis sauvegardée) avec les données de l'application.
Durant ce traitement les URLs à synchroniser sont groupées par fiche afin de conserver une cohérence forte au moment du calcul.
CalculateContentUrl
Cette classe comporte deux traitements, un de suppression (removeUrlForContent) appelé au moment de la suppression effective de la fiche, un de calcul (calculContentUrl) appelé à la modification d'une fiche. Il prend en paramètre le metatag avant et après la modification à l'origine de l'exécution de la méthode.
Ci-dessous le détail du traitement de calcul d'URL :
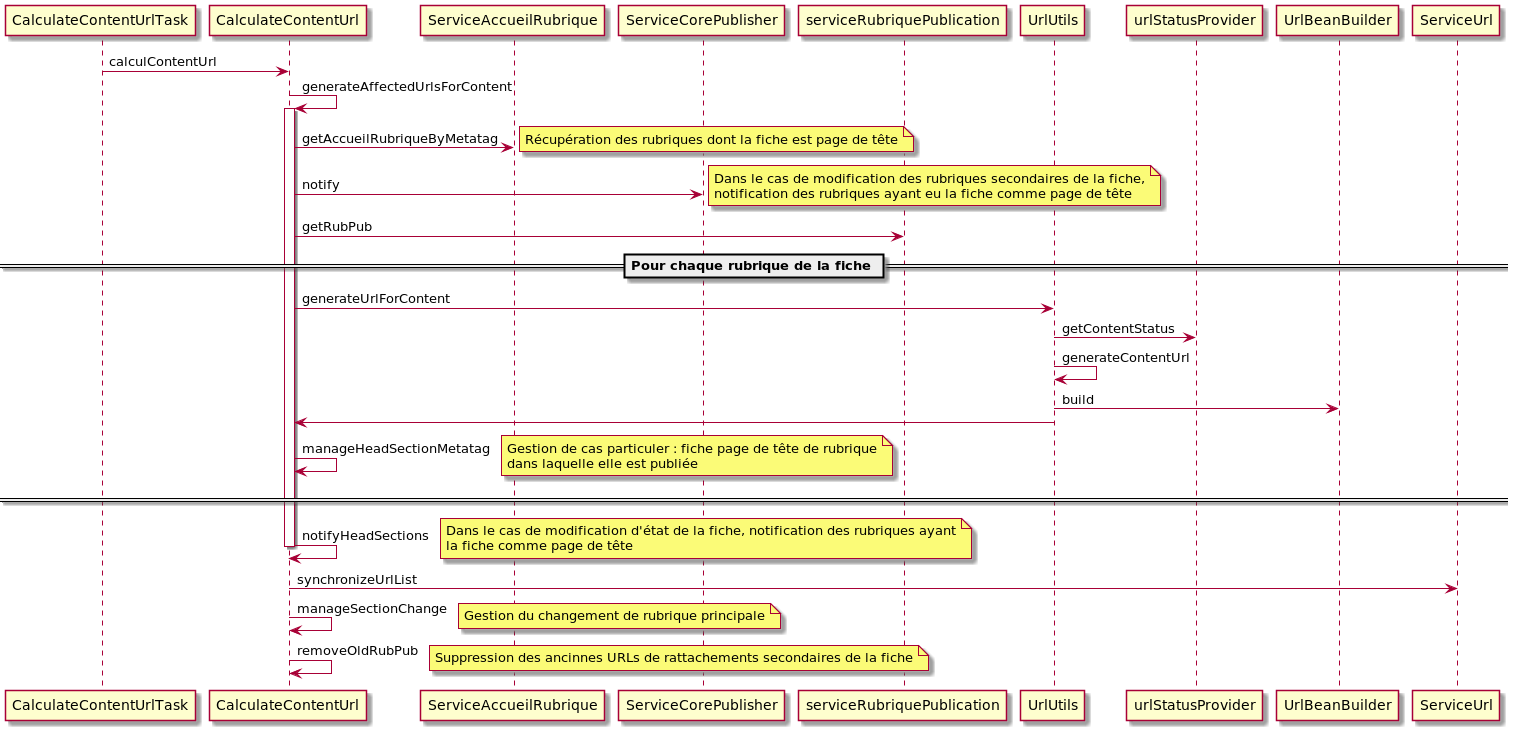
Dans la première partie de ce traitement on calcul les urls impactées par la modification en question. Pour ce faire les différentes rubriques de la fiche sont récupérées puis des URLs sont générées pour celles-ci. Des cas particuliers liés aux différentes rubriques sont gérés au passage de ce traitement.
Le traitement de synchronisation est ensuite appelé, voir la section détaillant son fonctionnement.
CalculateSectionUrl
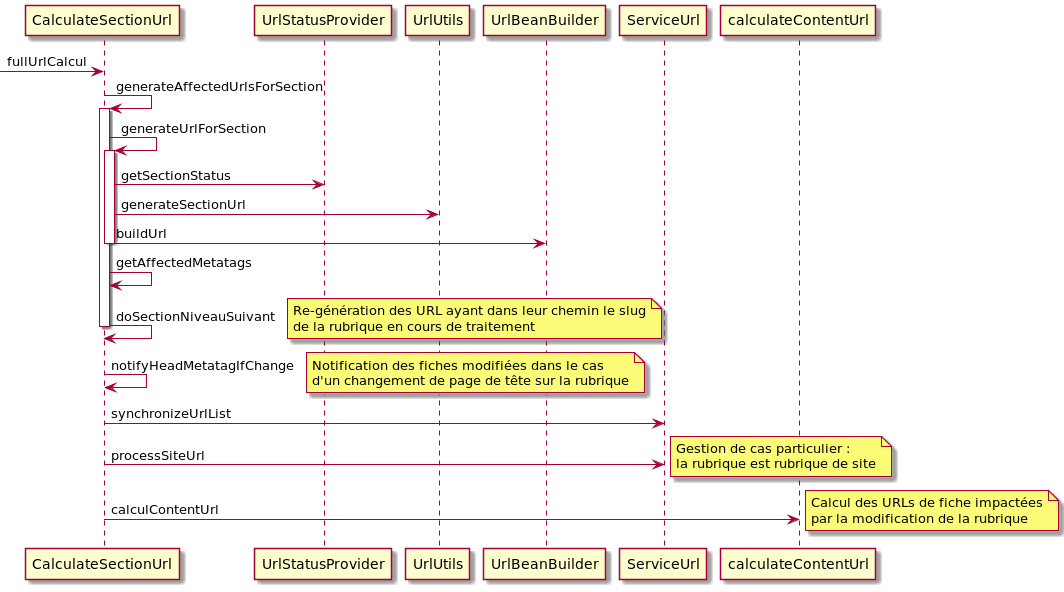
Ce traitement fonctionne sensiblement de la même manière que celui vu précédemment. Sa particularité réside dans le fait que sa complexité ne se situe pas au niveau du calcul des URLs du contenu car une rubrique n'a qu'une seule URL visible. Sa complexité se situe dans l'impact qu'il a sur l'ensemble des autres URLs.
En effet, dans la mesure ou le slug de la rubrique modifiée peut apparaître dans un grand nombre d'URL de différents contenus, il faut avoir en tête de notifier tous les contenus impactés par les changements sur la rubrique.
C'est ce qu'on peut voir dans la seconde partie du traitement, la méthode doSectionNiveauSuivant va remonter l'arbre des rubrique pour effectuer le traitement de recalcul sur les rubriques parentes et les contenus qui leur sont liés, et ce de manière récursive.
ServiceUrl
Le ServiceUrl permet de réaliser un trop grand nombre d'actions :
- Échanges avec la base de données autour de la table URL
- Calcul d'impact (affichage de popin lors de modification de contenus en backoffice)
- Synchronisation des URLs
- etc
Par souci de simplicité (sic), nous détaillerons ici que la partie synchronisation. Le point d'entrée de cette fonctionnalité est la méthode synchronizeUrlList qui s'attend à recevoir les URLs à synchroniser groupées par metatag (il peut y avoir un groupe d'URL sans metatag pour les URLs de rubrique).
L'utilité d'avoir les URLs regroupées est que pour chaque groupe on va pouvoir déterminer en une seule fois quelle est l'URL canonique du groupe d'URL. La synchronisation peut provoquer une modification d'URL canonique pour la fiche liée, dans ce cas, un recalcul est demandé par notification.
Pour chaque URL, quelle soit dans un groupe de metatag ou non, la méthode synchronizeUrl est appelée.
synchronizeUrl
Dans un premier temps, la méthode tente de repérer s'il existe une URL dans la base de données qui pourrait être ré-utilisée pour la nouvelle URL. Cela permet d'éviter d'ajouter un incrément sur des URLs quand cela n'est pas nécessaire et de traiter au passage les URLs qui n'auront plus lieu d'être après le traitement. Si l'URL réutilisée était de type canonique, alors elle est destituée (c'est à dire passée au statut "en ligne") de son statut avant d'être ré-utilisée.
C'est également à ce moment que l'URL est rendue unique en appelant MakeUrlUnique.
Ensuite l'URL est sauvegardée. Si elle est possède un statut canonique, on informe toute ses soeurs (URL pointant sur la même fiche) qu'il y a une nouvelle canonique à référencer.
S'il existe des URLs au statut "redirect" pointant sur la même rubrique et, dans le cas d'une URL de type fiche, la même fiche, alors on les informe toutes qu'elles doivent rediriger vers l'URL qui vient d'être créée.
Gestion des anciennes URLs
Afin de gérer les montées de version des applications présentent en prod avant la 6.7, un job de calcul des anciennes URLs a été mis en place, FullCalculateOldUrlTask. Celui-ci se charge de créer des URLs de type redirection vers les nouvelles URLs.
Dans le cas où certaines URLs seraient manquantes, le filtre OldUrlFilter écoute toutes les URLs correspondant au format d'avant la 6.7 et tente de rediriger vers la fiche censée lui correspondre.
Il est important de noter que pour fonctionner, ce job nécessite d'avoir l'ancien format de paramétrage des URLs dans sa configuration :
# Affichage des rubriques dans les urls
site.code_site.reecriture_rubrique_mode = 2
# Niveau à partir duquel la rubrique est précisée dans l'url
site.code_site.reecriture_rubrique_min = 100
# Niveau maximum pris en compte dans l'url Ex : /rub_min/rub_xxx/rub-yyy/rub_max/ma-page.htm
site.code_site.reecriture_rubrique_max = 100
Paramétrage
Propriétés
| Paramètre | Valeur | Commentaire |
|---|---|---|
| url.purge.maxdays | Par défaut : 365 | Permet de définir le nombre de jours de rétention des urls de redirection non utilisées |
Configuration dans l'application
| Paramètre | Valeur | Commentaire |
|---|---|---|
| Niveau montant max | Entier | À définir dans la configuration de site, permet de paramétrer le nombre de rubrique devant apparaître au maximum dans l'url depuis la racine |
| Niveau descendant max | Entier | À définir dans la configuration de site, permet de paramétrer le nombre de rubrique devant apparaître au maximum depuis le slug |